Introduction
This document is to describe the "2nd" version of Dark. The intent is to document the vision for Dark in the future, which can then be used to design a path from v1 to v2.
This document is being written simultaneously with "writing" a few Dark applications. I say writing because they are being written not against a real implementation, but on paper, to try and articulate the design of the language without getting bogged down on the implementation (v1 of Dark has an implementation which I already have a lot of experience with).
After this chapter, the rest of this document is organized by feature - we discuss what we learned from Dark v1 and what problems users experienced, then explain what we believe the solution is. Finally, each section will have a spec for v2 of the feature. This will expand to (or possibly link to) an implementation plan to migrate from v1 to v2.
Outline
Each section in the doc represents part of the Dark language, editor, platform, infrastructure, package manager, etc. Each section will follow a standard outline:
- Dark v1 problem
- List of problems with outline
- problem statement
- solution description
- status
- spec'ed, implemented, unknown, etc
- List of problems with outline
- v2 spec
- v2 language changes
- v2 editor changes
- v2 standard library changes
- etc
Implementation plan
The intent is to gradually migrate v1 into v2 -- that is, the current version will migrate into v2. Where this is not possible (for example, needing to remove a core type), we will use Dark's language versioning to migrate people to the new version. We hope to enable this with handler-by-handler granularity, allowing users to slowly move their code over in small pieces as they gain certainty that they won't be affected by the change.
Roadmap collaboration
There will at some point be a connection between this doc and the work being implemented, perhaps in some project management software. For now, Dark users are welcome to add GitHub issues in the Dark repo to discuss the contents of this roadmap, and in general to discuss or propose changes to Dark.
Goals of Dark v2
Overall goals of Dark
Dark's goals are to remove accidental complexity from writing backends, via:
- Instant infrastructure: create and scale infrastructure without thinking about it
- Deployless: Changes are safely deployed to production instantly
- making APIs as easy to call as functions
- Trace-drive development: use live requests to speed/improve development
- Integrated tooling: by integrating the editor, programming language and infrastructure, reducing a huge amount of surface area that can cause mistakes or take significant coding time.
Specific Goals of Dark v2
Get to Product market fit
Currently, we get 10 user signups a day, and on average, 0 of them stick. We do have developers who love Dark, but not enough.
The specific problem is that developers trying Dark today must trade one set of accidental complexity for another. While they get the advantages of Dark and they typically resonate with them, they also lose the advantages they have in most alternatives:
- developers need access to a large library of functions/modules/packages to access 3rd party services, such as Stripe, Twilio, Slack, etc -- this sort of thing is trivial in almost all other languages
- developers need to be able to trivially set up a user account system for their users (such as what they can accomplish using Firebase, Rails, Django, etc)
These are believed to be the major missing features. However, these missing features -- in order to be implemented with a great UX -- need the language and platform to expand to support having them be a great experience.
Fix issues from Dark v1
"v1" of Dark refers to the current state of Dark in August 2020. While this isn't really a v1, it serves as a reference point to discuss the shortcomings and challenges that we discovered by people using, creating, and maintaining it. Most parts of this document start by listing the problems in v1, and this document attempts to discuss overarching problems that users experienced.
Platformization
Dark v1 is very much a "product" - each feature was built and supported directly. Dark v2 attempts to be more of a platform, where more and more features are built in a way that they can be extended, or their own versions created.
For example, instead of having a dozen built-in refactoring commands, we'll expose the Dark language within the editor, allowing people to write transformations in the editor, in Dark itself.
Many of the things that are built into Dark could be put in the package manager, such as refactoring commands, templates, etc. That way developers could add refactoring tools that would allow them or other to , for example, create handlers to receive API-specific webhooks, build CRUD generators, build tooling to automatically create entire API modules from swagger files, or automatically upgrade from deprecated interfaces to newer ones.
In the platformizing spirit, we also want to write as much of Dark in Dark as possible. Since Dark is much easier to write than most other languages, writing as many features as possible in Dark will lead to faster iteration cycles and so better outcomes. It will also allow contributors to contribute more easily to core services and features.
Continuous Delivery
A core tenet of Dark is that everything is live. That means we need robust ways to carefully make changes to running applications. We have some already:
- all stdlib functions are versioned
- basic feature flag support exists
- static assets are all versioned
However, we want to support a situation where any change can be made carefully and incrementally, such as:
- versioning functions
- support carefully changing other features, such as types, secrets, and handlers
- db migrations
The rule here should be that all changes that affect the observable system to grandusers should be controllable and slow launched by the developer.
Support different access levels
Right now, there are no access types and Dark can only be accessed by signed-in users. We want to support:
- users trying dark without logging in
- using the editor (including live values) embedded in other docs
- public canvases that can be edited by anybody (safely, that is, so solving things like access to traces, passwords, etc)
- granular ACLs for organizations
Make Dark more robust
Dark v1 was built quickly and hackily, and was brittle in a number of senses. We cut every corner we could in an effort to get Dark far enough along to get feedback about how it works. Though we went back and reworked several components (in some cases several times) and iterated quite broadly, many problems surfaced because components of Dark were MVP quality.
This is true of product and language features (eg the error rail and feature flags), as well as simple usability (eg traces can be created, but not edited, searched, graphed, named, saved, etc). In a sense, we often only implement the "C" and "R" of CRUD.
I want to fully think through the problem spaces and their solutions, to deliver an excellent experience.
A number of examples:
- use a real type system to avoid all the hacks in v1
- use an async language/framework so that things like calling HTTP functions do not use all the resources, and so that functions like
sleepcan be supported - abandon OCaml for a place with more mature libraries & community (probably rust or F#)
- GraphQL: one reason that Dark isn't as robust as it could be is due to the overhead of supporting each CRUD operation in the client is that we need to create APIs for everything. I want to look at using GraphQL to ease that.
Improve the feeling of safety while coding
Dark feels unsafe to users. They feel reluctant to make changes because they don't know if they will work, or if they'll break things. We need ways to make this safer:
- unit tests on functions and handlers will make users feel safe
- type checking:
- by having type checking on functions and handlers, users can feel confident that their code will work
- error tracking
- highlight (and email users about) errors in their apps
- highlight data being sent that isn't being used by the app (eg form fields)
- is this the same as warn/error log messages?
- application understanding
- email users about their traffic so that they understand that their code works
- allow people search their traces for
- feature flags:
- make feature flags global and easier to use and understand
- fix size of traces
- fix editor layout
- the layout of the canvas
- education so that users can understand
Language
Dark v1 problems:
Dark v1 didn't have great types. Though technically there were some types under the hood, we didn't really expose them to users and they were only useful for checking the arguments and return values of functions.
However, the lack of types caused problems:
- DBs use a custom schema
- no way to validate handlers, which types would be useful for
- no enums to represent complex data
- records and dictionaries are sorta the same, which is horrible
- dictionaries are just dynamic typing
- autocomplete didn't work when a trace is missing (no way to know field names)
- we should be able to write code in the absence of traces
Built in types
Int
Ints are infinite precision integer values.
Dark v1 Problems
Infinite precision
Problem: Dark v1 integers are 63-bit integers, they should be infinite precision.
Solution: make them infinite precision instead using a BigNum library
Status: Spec'ed
JSON and integer size
Problem: when we automatically coerce integers to/from JSON, many JSON implementations do not support integers larger than 53 bits (for example, the Twitter API has "id" and "id_str" fields because sometimes the "id" is bigger than 53 bits)
Solution:
- Integer conversion into JSON should use a string if appropriate.
- Integer conversion from JSON should always be typed, and so if there's an int it can be parsed from a stringified integer literal if appropriate
Status: Not spec'ed
Negative numbers
Problem: The fluid editor does not allow negative numbers.
Solution: a UX for negative numbers is described below, it was quite straightforward.
Status: Spec'ed
Arithmetic errors
Problem: some arithmetic operations can lead to errors:
- division by 0
- modulus by 0
Solution: these should return Result (Int, IntError). One problem here is how we can make the error rail less cumbersome so that this isn't really irritating to handle.
Status: spec'ed
Integers of other sizes
Problem: it can be useful to have integers of specific sizes, in order to better model specific values or enforce overflow
Solution: we should add int8, int16, int32, int64, uint8, uint16, uint32, uint64
Status: not spec'ed
v2 Spec
v2 Language definition
type Expr =
| EInt { val = BigInt }
| ...
type Pattern =
| PInt { val : BigInt }
| ...
type Dval =
| DInt { val = BigInt }
| ...
type DType =
| TInt
| ...
v2 Standard library: Int
type Error =
| DivideByZero
// the same as V1
Int::absoluteValue(Int: a) -> Int
Int::add(Int: a, Int: b) -> Int
Int::clamp(Int: value, Int: limitA, Int: limitB) -> Int
Int::greaterThan(Int: a, Int: b) -> Bool
Int::greaterThanOrEqualTo(Int: a, Int: b) -> Bool
Int::lessThan(Int: a, Int: b) -> Bool
Int::lessThanOrEqualTo(Int: a, Int: b) -> Bool
Int::max(Int: a, Int: b) -> Int
Int::min(Int: a, Int: b) -> Int
Int::multiply(Int: a, Int: b) -> Int
Int::negate(Int: a) -> Int
Int::power(Int: base, Int: exponent) -> Int
Int::random_v1(Int: start, Int: end) -> Int
Int::remainder(Int: value, Int: divisor) -> Result
Int::sqrt(Int: a) -> Float
Int::subtract(Int: a, Int: b) -> Int
Int::toFloat(Int: a) -> Float
// different from v1
Int::divide(Int: a, Int: b) -> Result (Int, Error)
Int::mod(Int: a, Int: b) -> Result (Int, Error)
Int::sum(List Int: a) -> Int
v2 Editor changes
- support negative integers
- allow entering
-at the start of an integer to convert it to a negative number - allow deleting
-from the start of an integer to convert it back to a positive - if typing
-in a position that is not a binop, start a partial (already happens). Once a partial of-gets a number added, turn it into an integer
- allow entering
- remove the conversion when a number gets too big - no longer needed for infinite precision ints
Json serialization changes
TODO: wait til we figure out how JSON serialization works in Dark v2
String
Strings are unicode encode text. Specifically, string are immutable UTF-8 encoded sequences of Unicode code points.
Dark v1 problems
Concatenation
Problem: Users currently have to do concatenation like so:
"I am "
|> ++ user.name
|> ++ " and I am "
|> ++ (toString user.age)
|> ++ " years old"
Solution: Instead, we'd like to support string interpolation
"I am ${user.name} and I am ${user.age} years old"
Status: language definition spec'ed. Interaction model not spec'ed
Special characters
Problem: To enter a newline, carriage return, tab, or other special character, you have to paste them directly. You can't type any of them. Related to this, the display of these tokens in the editor is broken.
Solution: support using escape characters (\) to support them (\n, \r, \t, \\, \", etc). Describe the complex UX for adding them, deleting, displaying, and editing them, in the spec below.
Status: language definition spec'ed, interaction model not spec'ed
Emoji
Problem: I think the editor does not support proper unicode - I'm not sure.
Solution: the editor should support entering all LTR Unicode text (RTL can wait until Dark v3) - if you can type it into the browser, we should support it in the editor.
Status: problem not understood, not spec'ed
String length
Problem: String length is determined in O(n) time.
Solution: String length should be cached as part of the string. Using a better string implementation would help solve this.
Status: spec'ed
Shortened display
Problem: We wrap strings at 40 characters to make lines not run on forever. This has a number of annoying problems:
- sometimes the string is only 41 character and it looks bad
- sometimes the line has more room than 40 characters and it looks dumb
- sometimes the line has builtin line breaks, but it breaks off length instead
- We should do a better job of wrapping that takes into account the entire length of the line, and make 40 configurable.
Solution: TODO
Status: not spec'ed
Cursor affinity
Problem: the cursor can be in two different places which logically mean the same thing (the end of a line, and the start of the subsequent line). This leads to "cursor affinity" problems.
Solution: TODO: this was written down somewhere.
Status: Not spec'ed
v2 spec
Strings are unicode, and character are unicode “characters” (if it appears as one character on the screen, that’s a “character” in Dark).
Specifically, string are immutable UTF-8 encoded sequences of Unicode code points. Chars are “Extended Grapheme Clusters”. (A codepoint is some bytes that implement unicode characters, a grapheme is some codepoints forming a unicode entity, such as an emoji; an EGC is some graphemes, used to handle things like emojis which combine to form a single emoji).
v2 Language definition
type string = # unicode supporting type, should include length
type stringSegment =
| Text of string
| InterpolatedExpr of expr
type Expr =
| EString of stringSegment list
| ...
type Pattern =
| PString of string list
| ...
type Dval =
| DString of string
| ...
type DType =
| TString
| ...
Escaped characters can be stored as their actual values in the string, and displayed/entered differently in the editor.
v2 Standard library
type StringError =
| FloatConversionError
| IntegerConversionError
// same as v1
String::append_v1(String: s1, String: s2) -> String
String::base64Decode(String: s) -> String
String::base64Encode(String: s) -> String
String::contains(String: lookingIn, String: searchingFor) -> Bool
String::digest(String: s) -> String
String::dropFirst(String: string, Int: characterCount) -> String
String::dropLast(String: string, Int: characterCount) -> String
String::endsWith(String: subject, String: suffix) -> Bool
String::first(String: string, Int: characterCount) -> String
String::fromChar_v1(Character: c) -> String
String::isEmpty(String: s) -> Bool
String::join(List l, String separator) -> String
String::last(String: string, Int: characterCount) -> String
String::length_v1(String: s) -> Int
String::padEnd(String: string, String: padWith, Int: goalLength) -> String
String::padStart(String: string, String: padWith, Int: goalLength) -> String
String::prepend(String: s1, String: s2) -> String
String::replaceAll(String: s, String: searchFor, String: replaceWith) -> String
String::reverse(String: string) -> String
String::slice(String: string, Int: from, Int: to) -> String
String::slugify_v2(String string) -> String
String::split(String s, String separator) -> List
String::startsWith(String: subject, String: prefix) -> Bool
String::toBytes(String: str) -> Bytes
String::toFloat_v1(String: s) -> Result (Float, StringError)
String::toInt_v1(String: s) -> Result (Float, StringError)
String::toList_v1(String: s) -> List Character
String::toLowercase_v1(String: s) -> String
String::toUppercase_v1(String: s) -> String
String::trim(String: str) -> String
String::trimEnd(String: str) -> String
String::trimStart(String: str) -> String
// Maybe could be better
String::htmlEscape(String html) -> String
String::newline() -> String
// Move to UUID module
String::toUUID_v1(String: uuid) -> Result (UUID, StringError)
// Different in v2
String::foreach_v1(String: s, Block f) -> String
String::fromList_v1(List l) -> String
String::random_v2(Int: length) -> String // length < 0 means empty string
v2 Interaction model
String escaping
TODO
Interpolation
TODO
Character
Characters should be an Extended Grapheme Cluster, corresponding to a single display character.
Chars are “Extended Grapheme Clusters”. (A codepoint is some bytes that implement unicode characters, a grapheme is some codepoints forming a unicode entity, such as an emoji; an EGC is some graphemes, used to handle things like emojis which combine to form a single emoji).
Dark v1 problems
Can't create characters
Problem: Characters were implemented, but you couldn't create one.
Solution: implement characters creation
No character stdlib
Problem: Characters were implemented but there were no functions on characters (they were on strings instead)
Solution: Add functions the use characters
v2 spec
v2 Language definition
type egcChar = // type suitable to hold an EGC
type Expr =
| EChar { val = egcChar }
| ...
type Pattern =
| PChar { val : egcChar }
| ...
type Dval =
| DChar { val = egcChar }
| ...
type DType =
| TChar
| ...
v2 Standard library: dark/stdlib/Char
// New
Character::toString(Char: c) -> String
String::map(String: s, (Char -> Char)) -> String
String::toList(String: s) -> List Char
String::fromList(l : List Char) -> String
v2 Editor changes
- allow entering characters
'creates a partial showing''- entering a character turns the partial into an ECharacter (eg
'a') - entering another character turns it into a Partial with both characters (eg
'ab') - converting it back into a properly formed character turns it into one
- typing
'when when your cursor is on the closing quote skips over it
- escaping should be supported
- common expected escapes: \n, \r, \t
- escapes that are needed for the text to work \\, \'
- allow a specific byte: \xhh (hex escaping)
- could possibly allow octal escaping too
- escape sequences should be clear to the user (a different color)
- escape sequence should have a clear doc explaining how it works and what the user is looking at
- the expr should be a partial while the
\is not followed by a valid character
Float
Floats are 64-bit IEEE-754 arithmetic, with what I hope are improvements. Dark's floats were designed to not support infinity or overflow. Those are sentinel values which can sneak into logic, and continue to propagate. Instead, we want to use results to handle these errors.
Dark v1 problems
Operators
Problem: Dark's operators (+, -, *, etc) work on integers. In Dark v1, we use Float::+ instead, which doesn't suck but isn't great
**Non-solution: **We speculated that we could use the editor to simply hide the Float:: part. However, that doesn't allow polymorphism, you can't have a library that takes numbers of any kind and (for example) sums them.
Solution: use traits to support reuse of common operators for different types
Status: Not spec'ed
Float entry problems that convert to 0
TODO
Status: Problem not understood
Inf and NaN
Problem: In Dark v1, it's possible to accidentally create Inf and NaN, but it was not really possible to use them.
Solution: prevent creating Inf or NaN. Any functions which (internally) create invalid floats will return Results instead.
Status: Spec'ed, not implemented
Negative 0.0
Problem: it's possible to have negative 0.0. This is a confusing part of floats.
Solution: TODO
Status: problem not understood, solution unknown
Support other representations
Problem: v1 only supports decimalized floats, like 5.6. It should also support exponent style like 6.02e23
Solution: Also support exponent format
Status: Representation is spec'ed. Interaction model not spec'ed.
Floats don't support negatives
Problem: same as ints
Solution: copy the proposed interaction model from ints
Status: not spec'ed
v2 spec
v2 language definition
Same as V1, except we represent a float better.
type Sign =
| Plus
| Minus
type floatRep = {
wholeNumberPart : Int64,
fractionalPart : Int64
exponentExists : Bool
exponentSign : Sign
exponentPower : Int64
}
type Expr =
| EFloat of floatRep
| ...
type Pattern =
| PFloat of floatRep
| ...
type Dval =
| DFloat of double
| ...
type DType =
| TFloat
| ...
Examples
5..60.6-678.234-6.436E-567
Float stdlib functions
type Error =
| FloatOverflowError
// same as v1
Float::absoluteValue(Float: a) -> Float
Float::ceiling(Float: a) -> Int
Float::clamp(Float: value, Float: limitA, Float: limitB) -> Float
Float::floor(Float: a) -> Int
Float::greaterThan(Float: a, Float: b) -> Bool
Float::greaterThanOrEqualTo(Float: a, Float: b) -> Bool
Float::lessThan(Float: a, Float: b) -> Bool
Float::lessThanOrEqualTo(Float: a, Float: b) -> Bool
Float::max(Float: a, Float: b) -> Float
Float::min(Float: a, Float: b) -> Float
Float::negate(Float: a) -> Float
Float::round(Float: a) -> Int
Float::roundDown(Float: a) -> Int
Float::roundTowardsZero(Float: a) -> Int
Float::roundUp(Float: a) -> Int
Float::sqrt(Float: a) -> Float
Float::subtract(Float: a, Float: b) -> Float
Float::truncate(Float: a) -> Int
Float::sum(List Float: a) -> Float
// different from v1
Float::add(Float: a, Float: b) -> Result (Float, Error)
Float::subtract(Float: a, Float: b) -> Result (Float, Error)
Float::divide(Float a, Float b) -> Result (Float, Error)
Float::power(Float base, Float exponent) -> Result (Float, Error)
Float::multiply(Float: a, Float: b) -> Result (Float, Error)
Tuple
Dark v1 does not have tuples. Dark v1 allowed different types in the same list, though, which was not a great experience as the rest of the language mostly expected the language to be typed.
Goals
Tuples are useful for situations where you want to group information together but do:
- do not want a full blown record
- want heterogeneous types
- want destructuring
V2 definition
type Expr =
| ETuple { exprs : List Expr }
| ...
type Pattern =
| PTuple { pats : List Pattern }
| ...
type Dval =
| DTuple { vals = List Dval }
| ...
type DType =
| TTuple { contents = List DTyple }
| ...
Interaction model
let (myString, myInt) = ("str", 6)
Creation:
'let ' =>
let |___ = ___
( =>
let (|) = ___
myString =>
let (myString|) = ___
, =>
let (myString, |___) = ___
'myInt) = ' =>
let (myString, myInt) = |___
( =>
let (myString, myInt) = (|)
'"str", ' =>
let (myString, myInt) = ("str", |___)
5) =>
let (myString, myInt) = ("str", 5)|
Standard library
// Access
Tuple2::first ('a,'b) -> 'a
Tuple2::second ('a,'b) -> 'b
// Creation
Tuple2::pair ('a, 'b) -> ('a,'b)
// Manipulation
Tuple2::mapFirst (('a,'b), ('a -> 'c)) -> ('c, 'b)
Tuple2::mapSecond (('a,'b), ('b -> 'c)) -> ('b, 'c)
Tuple2::mapBoth (('a,'b), ('a -> 'c), ('b -> 'd)) -> ('c, 'd)
Tuple2::swap (('a,'b)) -> ('b, 'a)
// And all the equivalents for Tuple3
// Also possibly bonus functions from https://package.elm-lang.org/packages/TSFoster/elm-tuple-extra/latest/Tuple3
Changes in existing libraries:
List.zip_v1(List 'a, List 'b) -> Option (List ('a, 'b))
List.zipShortest_v1(List 'a, List 'b) -> List ('a, 'b)
List.unzip_v1(List ('a, 'b) -> (List 'a, List 'b)
Dict.fromList_v1(List ('a, 'b)) -> Option (Dict 'a 'b)
Dict.fromListOverwritingDuplicates_v1(List ('a, 'b)) -> Dict 'a 'b
Dict.toList_v1(Dict 'a 'b) -> List ('a, 'b)
There should be some version of a HttpClient function that takes tuples, as it is legal to have multiple headers of the same type and so tuples rather than dicts represent the correct type. Since we expect users to use built-ins for headers (such as Http::jsonContentType), this seems doable soon.
Bool
Booleans are true or false
Dark v1 Problems
None
v2 Spec
v2 Language definition
type Expr =
| EBool { val = bool }
| ...
type Pattern =
| PBool { val : bool }
| ...
type Dval =
| DBool { val = bool }
| ...
type DType =
| TBool
| ...
v2 Standard library
// same as V1
Bool::and(Bool, Bool) -> Bool
Bool::not(Bool) -> Bool
Bool::or(Bool, Bool) -> Bool
Bool::xor(Bool, Bool) -> Bool
// removed
// no nulls anymore (also, shouldn't have been in the bool namespace)
Bool::isNull(Any check) -> Bool
Bool::isError(Any check) -> Bool
v2 Editor changes
None
List
Lists and Arrays use the same datatype, called Lists. The Dark compiler will in the future optimize their implementation to support good algorithmic complexity and performance for whatever you use them for.
Lists should be used for all “I want a sequence of things” situations, including iterating across them, random access, push/pop, etc.
Dark v1 Problems
No pattern matching on lists
Problem: patterns don't support lists yet
Solution: implement
Status: Spec'ed or not spec'ed
Fake values are sometimes in lists
Problem: errors, errorrails and incompletes can be put in lists, if we're not careful
Solution: Though we have mostly been careful, it would be useful to try and fuzz functions, or add logging, or something to ensure that this doesnt happen
Status: Unspeced
It's possible to have heterogenous lists
Problem: If you have a list of ints, you can add a string to it
Solution: This might be solved by having a type checker tell you what you're doing wrong. Or perhaps we actually track the type of a list and raise an error if the wrong type is inserted
Status: still unclear on solution
v2 Spec
v2 Language definition
type Expr =
| EList { list : List Expr }
| ...
type Pattern =
| PList { val : List Pattern }
| ...
type Dval =
| DList { val = List Dval }
| ...
type DType =
| TList of DType
| ...
v2 Standard library
List::append(List 'a, List 'a) -> List 'a
List::drop(List 'a, Int) -> List 'a
List::dropWhile(List 'a, ('a -> bool)) -> List 'a
List::empty() -> List 'a
List::filterMap(List 'a, ('a -> Option 'b)) -> List 'b
List::filter_v2(List list, ('a -> bool)) -> List 'a
List::findFirst_v2(List 'a, ('a -> bool)) -> Option 'a
List::flatten(List (List 'a)) -> List 'a
List::fold(List 'a, 'b, ('a -> 'b -> 'b)) -> 'b
List::getAt_v1(List 'a, Int) -> Option 'a
List::head_v2(List 'a) -> Option 'a
List::indexedMap(List 'a, (Int -> 'a -> 'b)) -> List 'b
List::interleave(List 'a, List 'a) -> List 'a
List::interpose(List 'a, 'a) -> List 'a
List::isEmpty(List 'a) -> Bool
List::last_v2(List 'a) -> Option 'a
List::length(List 'a) -> Int
List::map(List 'a, ('a -> 'b)) -> List 'b
List::map2(List 'a, List 'b, ('a -> 'b -> 'c)) -> Option (List 'c)
List::map2shortest(List 'a, List 'b, ('a -> 'b -> 'c)) -> List 'c
List::member(List 'a, 'a) -> Bool
List::push(List 'a, 'a) -> List 'a
List::pushBack(List 'a, 'a) -> List 'a
List::randomElement(List 'a ) -> Option 'a
List::range(Int, Int) -> List Int
List::repeat(Int, 'a) -> List 'a
List::reverse(List 'a) -> List 'a
List::singleton('a) -> List 'a
List::sort(List 'a) -> List ;a
List::sortBy(List 'a, ('a -> 'b)) -> List 'a
List::sortByComparator(List 'a, ('a -> Int)) -> Result (List 'a) String
List::tail(List 'a) -> Option (List 'a)
List::take(List 'a, Int count) -> List 'a
List::takeWhile(List 'a, ('a -> Bool)) -> List 'a
List::uniqueBy(List list, ('a -> 'b)) -> List 'a
// To remove, see Tuples
List::unzip(List) -> List
List::zip(List, List) -> Option
List::zipShortest(List, List) -> List
v2 Editor changes
- support for list patterns
- support for cons perhaps?
Dictionary
Dicts are maps from a certain key type to a certain value type. The key must currently be a string. The value can be any type but all elements of the Dict are the same type (not currently enforced).
Dicts are different than records: dicts can have arbitrary keys.
Dark v1 Problems
Dictionaries are the same as records
Problem: Right now, both dictionaries and records are represented by a DObj and a TObj. We need to separate them.
Subproblem: the only way to update a "record" is with Dict::set.
Solution: add a syntax for updating records. In existing functional languages, they use { existingValue with fieldName1 = newValue1; fieldName2 = newValue2 }
Status: not speced
Subproblem: The "syntax" to create dicts and records is overloaded. Both use { field : value } (as both are the same thing right now. If we split them, we need a way to disambiguate which one you're creating.
Solution option 1: Add a new syntax for records. For example, we might do:
Person {.
The big advantage here is that the autocomplete would create a bunch of new fields to fill in the object, like so:
Person {
name : ___ // "string" placeholder text)
age : ___ // "int" placeholder text
}
Solution option 2: Add a new syntax for dictionaries. For example, we might do:
let myDict = dict{
___ : ___ // would be useful to have a prompt to tell you to use quotes here
}
This would have a number of other benefits
Subproblem: What do we do with existing records and objects? Do they become records or objects or a third legacy DObj?
Solutions:
- Add a new dictionary type, that is not compatible with DObj
- It would need new functions that are type compatible
- It would allow keys of any single type
- The values would homogenous
- dot syntax would not be supported (use
Dict::getinstead) - record syntax would not be supported
- could support dot
- Remove hack where we allow hyphens in record names
- Since people use maps for headers, switch headers to string pairs
- Add a type checker which distinguishes between Dicts and Record
- DObj would become just a record
- old
Dict::functions would be for records, and would be deprecated. They could even be renamed toRecord::for now, until we add syntax for the new stuff. We could automatically transition them to the new stuff - dot access could instead be
- old
Status: TODO
Dictionaries are string only
Problem: Right now, you can't have a dictionary of other things
Solutions:
- Add a syntax for updating records so that we don't have to use Dict::set
- Add a type checker which distinguishes between Dicts and Record
- I wonder if we could use the same syntax for both?
- Stop using the DObj for both
- will likely need a new version of the language for this
Status: TODO
It's possible to have heterogenous dictionaries
Problem: If you have a dict of ints, you can add a string to it
Solution: This might be solved by having a type checker tell you what you're doing wrong. Or perhaps we actually track the type of a dict and raise an error if the wrong type is inserted
Status: TODO
v2 Spec
v2 Language definition
v2 Standard library
Dict::filterMap(Dict 'k 'v, ('v -> Option 'b)) -> Dict 'k 'b
Dict::filter_v1(Dict 'k 'v, ('v -> bool)) -> Dict 'k 'v
Dict::isEmpty(Dict dict) -> Bool
Dict::keys(Dict dict) -> List
Dict::map(Dict dict, Block f) -> Dict
Dict::member(Dict dict, Str key) -> Bool
Dict::merge(Dict left, Dict right) -> Dict
Dict::remove(Dict dict, Str key) -> Dict
Dict::set(Dict dict, Str key, Any val) -> Dict
Dict::singleton(Str key, Any value) -> Dict
Dict::size(Dict dict) -> Int
Dict::toJSON(Dict dict) -> Str
Dict::toList(Dict dict) -> List
Dict::values(Dict dict) -> List
// Remove string-only
Dict::get_v2(Dict Str 'v, Str) -> Option 'v
Dict::get_v2(Dict Str 'v, Str) -> Option 'v
// TODO use tuples
Dict::fromList(List entries) -> Option
Dict::fromListOverwritingDuplicates(List entries) -> Dict
v2 Editor changes
Option
Description
Dark v1 Problems
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Result
Description
Dark v1 Problems
Results are not polymorphic
Problem: The result type is TResult, and doesn't have parameters for its contents
Solution: Replace TResult with TResult(successType, errorType)
Status: Not spec'ed
Results are a special type
Problem: Results should be a regular type in the standard library, not one built into the implementation
Solution:
-
remove
DResult- replace with
DEnum(name : ConstructorName, args : Dval list)
- replace with
-
remove
TResultfrom types- add type definitions to standard library
- replace with instance of enum type
Status: Not spec'ed
v2 Spec
v2 Language definition
type Dval =
DEnum(ConstructorName, args : List<Dval>)
...
v2 Standard library
let builtinTypes =
[
]
v2 Editor changes
Set
Description
Dark v1 Problems
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Ref
Description
Dark v1 Problems
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Regex
Dark v1 thoughts
Dark v1 does not have regex, due to the technical challenge that the OCaml native regex implementation we used (re2) does not compile to JS.
We want to use a regex implementation which can not be DOSed. Parse.com apparently had big problems with their regex.
Users asked for regex a lot.
I've never seen a regex implementation that was as easy to use as Perl's, so that's what we're aiming for (in terms of simplicity, not necessarily syntax):
# does it match?
if ($str =~ /ul/) { ... }
# capturing
if($line =~ /name:\s+(\w+\s+\w+),\s+period:\s*(\d{4}\-\d{4})/)
$composers{$1} = $2;
Description
Dark v1 Problems
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
UUID
Dark supports UUIDs directly.
Dark v1 Problems
UUID is a special type in the runtime, not a type defined using the type system
Problem: There should be very few "special" types, and there's no reason that UUIDs should be one of them
Solution: Add a built-in UUID type, presumably an alias of binary or perhaps a record with a bunch of u8s
Status: TODO
String::toUUID is in the wrong module
Solution: Rename String::toUUID to UUID::parse
Status: TODO
v2 Spec
v2 Language definition
TODO
v2 Standard library
// Removed
String::toUUID_v1(Str uuid) -> Result
// Added
UUID::parse(String) -> Result UUID Unit
Uuid::generate() -> UUID
v2 Editor changes
Bytes
Non-unicode sequences of bytes are supported as the Bytes type.
Dark v1 Problems
HTTP body is a string (if not json)
Problem: We automatically convert HTTP bodies into strings, even if it's not valid Unicode
Solution: Use types to specify how to convert bytes to bodies, such that the logical code is as follows body |> Bytes::toString |> Json.Deserialize<MyType>
Status: TODO
HTTP request raw values are strings but they might not be
Problem: HTTP request raw field is a string, but
Solution:
Status: Spec'ed or not spec'ed
HTTP client calls use Strings, so you can't send bytes
Problem: We'd like to be able to make raw http calls
Solution: Add a type, or even middleware, to HTTP calls such that we can use more types
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Null
As a temporary hack, Dark supports null. This allows us handle JSON while we build out enough type-system support to allow them to be replaced by Option.
Null is mostly useful for comparing against incoming JSON and results of HttpClient calls. When returning JSON or making HttpClient calls, you can use Options instead and they will be converted properly to null in the JSON output.
Dark v1 Problems
Nulls can appear in JSON
Problem: Nulls shouldn't really exist, but they do because
Solution: Add a way to have types in HTTP handlers, and when retrieving data over Http APIs.
Status: TODO
Nulls can appear in the database
Problem: It is technically possible to add nulls to the database, though it shouldn't really be allowed.
Solution: We need some sort of way to migrate this to a newly typed world. A good way to start would be to determine how common null values are in the database, and to go from there.
Status: TODO
**What to do with existing uses of **Null?
Problem: When we've identified how to not require null anymore, we still have to do something with existing code that uses Null
Solution: Probably make a new version of the dark language without null and deprecate the old one. Another alternative is to convert null into () (unit, or empty tuple).
**Alternative solution: **convert all uses of null into Json::Null_v0, which would be deprecated
Status: TODO
v2 Spec
v2 Language definition
Remove nulls
v2 Standard library
// remove
Bool::isNull
Control-flow
Concurrency / parallelism
Functions
Higher o
Higher-order functions
Dark v1 problems
Dark's higher order functions could only take lambdas. For example:
List::map [1,2,3] (Int::add 1) // not possible
List::map [1,2,3] (\i -> Int:add i 1) // workaround
However, this was allowed in pipes:
[1,2,3]
|> Int::add 1
But this came with problems of it's own:
[1,2,3]
|> Int::sub 1 // [0,1,2] or [0,-1,-2]?
BinOps
- how do we version binops?
- How do we make
+work for floats as well as ints (and dates, etc)
Function definitions
Dark v1 Problems and solutions:
Function space
Problem: function definitions were in the "function space", which confused people.
Solution: the function space is not important, but keeping functions off of the main canvas is a key part of the Infrastructure view metaphor. I think we need to make it clearer whats happening here, possibly by making better animations as we transition from handler to caller.
I welcome other suggestions for how to improve this.
Parameters are not fluid
Problem: Parameters use a non-fluid way to enter them. We want everything to be fluid.
Solution: Make function definitions fluid, including parameters and docstrings.
One thing that's nice about function parameters is that they're draggable - I think we could augment many fluid things by making them draggable (eg let definitions, record entries, etc).
Docstrings in user functions
Problem: Dark v1 doesn't have docstrings. We had a [PR for it](https://github.com/darklang/dark/pull/2571) but it had weird behaviour due to blankOrs.
Solution: docstrings should be part of the structured editor definition of a function, using a fluid mechanism.
Docstrings aren't used properly in stdlib
Problem: Though we support docstrings
Solution: Go through the stdlib and use docstrings properly, according to the guide.
Problem: we support docstrings for individual parameters (as well as the parameters of lambda functions) but we don't use them
Solution: go through the stdlib and add docstrings for individual parameters. Show those docstrings in the UI when your cursor in on a parameter.
User Functions don't have continuous delivery built-in
Problem: there isn't a way to safely make a new version of an existing function that's used by other functions or handlers.
There is, conceptually at least, a good solution for continuous delivery of a handler:
- lock the handler when used
- only allow changes via feature flags
For functions, versioning is a better strategy, as it allows handlers to use feature flags to change which version they call.
Solution: We need to write down the exact UX of how this works, start to finish. How do the flags get set, when do functions lock and version, and what happens when we have a new version of a function that's down the callgraph?
Methods
Problem: most people coming to dark are used to calling methods on "objects" and get confused when they type "hello world".toUppercase and discover not only that there's no function called "uppercase", but also that they're not offered any functions. This is because Dark uses pipes, and doesn't do function dispatch.
Non-Solution: one solution would be like what Rust does solution: offer both functions and methods. If the function is implemented on that type, then it's available as a method, but you can also have methods. However, this is a little frustrating, as you can (afaik) only chain methods, you can't add a function call to that chain. Dark uses piping for chaining calls together nicely, so we should use that.
Solution: when a developer types '.' after an object, offer not just the fields of the struct in the autocomplete, but also the functions that the user would expect to find as methods. These would include at least anything that has the type as the first parameter.
TODO:
package manager from the start
can we implement built-in Dark functions via the package manager
what is the story with namespacing (types vs modules)
How should tests work? Should they be for a specific
TODO: partial application/currying
TODO: optional parameters
Versioning:
- functions should be versioned, but we haven't got a good system
- idea: functions called by locked handlers are locked
- the challenge is that when you change a function, you change the entire call tree
- can you add a feature flag to a function?
- make it easy to clone another version
Package manager
We want a package manager, so stdlibs need to fit into this. The namespace of stdlib is dark/stdlib/. Because functions
Example
def range_v0:
start : Int => The lower end of the range
end : Int => The upper end of the range. This is not
included in the output.
Function calls
BinOp calls
Function calls
Lambda
Pipe
Match
Let
Dark v1
Dark v1 had this defintiion of let:
type Expr =
| Let { lhs : string, rhs : expr, body : expr }
| ...
// No pattern, dval, or dtype
This had a number of problems:
- no support for destructuring
- users expected Dark to be a list of statements followed by an expr, but they got a single expr with unexpected semantics
- esp due to refactoring tools, which didn't necessarily handle this well.
Problem
Users expect Dark to be a list of statements followed by an expr. The actual semantics (a single expr, which allows nested expressions) confuses users. One particular manifestation is that the refactoring tooling does not have expected behaviour.
Solution
- much more testing for refactoring functions, especially in the presence of nesting
- TODO: more needed here
V2 definition
type Expr =
| Let { lhs : pattern, rhs : expr, body : expr }
| ...
// No pattern, dval, or dtype
If
An if statement in Dark is a conditional,
Dark v1
type Expr =
| If { cond : Expr, thenbody : Expr, elsebody : Expr }
| ...
// No pattern, dval, or dtype
Problem
In Dark v1, the interpreter allows an non-false, non-fake value to return true.
Solution
Dark v2
Type System
Dark v1 problems
Dark v1 didn't have great types. Though technically there existed some types under the hood, we didn't really expose them to users and they were only useful for checking the arguments and return values of functions.
Lack of enums
Input Validation
DB schemas
Problem: Datastores used a custom schema. This meant that we couldn't use the same types to validate input
However, the lack of types caused problems:
- DBs use a custom schema
- no way to validate handlers, which types would be useful for
- no enums to represent complex data
- records and dictionaries are sorta the same, which is horrible
- dictionaries are just dynamic typing
- autocomplete didn't work when a trace is missing (no way to know field names)
- we should be able to write code in the absence of traces
Real types
Dark v1 problems
- Worker
eventvariables do not have types, and so they can receive types of any shape - HTTPClient calls automatically convert JSON into objects of the right shape
Description
Dark v1 Problems
Datastores use a "schema"
Problem: Datastores use this totally custom thing called a "schema". It should obviously be a type instead.
Solution: Figure out how to migrate from schemas to types
Status: TODO
HTTP handlers create types dynamically
Problem: HTTP's request variable are magically converted into JSON. The HTTP middleware does not have real types.
Solution:
- add a way of instantly creating a type from a trace
- allow adding types to the middleware so that they can be validated
- return 400 if they're not the right shape, possibly with a nice error message
Status: Spec'ed or not spec'ed
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Type checking
Dark v1 problems
A big issue is that Dark v1 didn't support type checking directly. Instead, the execution engine sometimes produced error which highlighted and propagated type errors.
Because there was no type checking, programs were often broken, but this was hard to see if it was not triggered by a particular trace.
This particularly affected the automatic JSON parsing from HTTP requests and the result of HTTPClient calls, which essentially used dynamic typing.
Error Rail
The error rail isn't great, people get confused and it doesn't really do what we want.
Result.map and Option.map, etc, shouldn't go to the error rail
What if we replaced it by something from another language (eg Rust/coffeescript's ? or F#'s let! (which is bind).
let!
In F#:
let! x = 5 / 6
let! y = x + 2
return y + 1
Desugars into
Bind(5 / 6, fun x ->
Bind(x + 2, fun y ->
(y + 1)
Perhaps that's a better approach. It would imply needing a Bindable Trait or similar. See https://fsharpforfunandprofit.com/posts/computation-expressions-bind
Records
Dark v1 problems
- updating records
- confusion between records and dicts
You access records fields by:
myRecord.x
If the field doesn't exist: DError. But there will be a type checker to ensure the field exists
Description
Dark v1 Problems
Problem: Records and dicts are the same thing.
In v1 of Dark, there are only DObjs, and both records and dictionaries use the same value type. This leads to significant confusion:
- It's unclear whether the
{}syntax creates a record or a dict Dict::functions work on Records- Record access syntax (
x.y) works on Dictionaries
Solution:
A solution needs to hit the following notes:
- how do we create records and dictionaries
- what do we do with the current records and dictionaries
One possible solution that was considered was to have a type constructor, like in rust. This had the problem of what happens if you pass a record into something with another type but the same shape, when you have polymorphic traits on it (actually this problem might exist anyway).
Actual solution:
- existing things become records (
DObj becomes DRecord)- existing
Dict::values work on records, and are deprecated and replaced with syntax
- existing
- new dictionary type (
DDict)
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Enums
Description: TODO
Dark v1 Problems
Built-in enums are not real types
Problem:
The existing built-in enum types (Result and Option) are partially hardcoded.
Expressions allow EConstructor, but Dvals use DResult and DOption, while
DType uses DResult and DOption.
Solution:
- Allow Enum types in the standard library
- Allow versioning and namespacing for constructors
- Reimplement DResult and DOption using the builtin enum type
- migrate stored programs, stored values in the User DB, stored values in traces
Status: TODO
Users cannot create their own enum types
Problem: Once we have enums created in the standard library, we still need to allow users to create them.
Solution:
- UI work (piggyback off record work)
- versioning (piggyback off record work)
- namespaces (piggyback off record work)
- storage somewhere (piggyback off record work)
Status: TODO
Cannot pipe to constructors
Problem: you can't pipe to a constructor
- account for constructors with multiple
Status: Not designed
v2 Spec
v2 Language definition
type StdlibTypeName =
{ module_ : string
typeName : string
version : int }
type PackageTypeName =
{ owner : string
package : string
module_ : string
typeName : string
version : int }
type UserTypeName = {
typeName : string
version : int
}
type TypeName =
| StdlibTypeName of StdlibTypeName
| PackageTypeName of StdlibTypeName
| UserTypeName of UserTypeName
type Parameter =
{ name : string
typ : DType
description : string }
module Enum =
type Variant = {
constructorName : string
parameters : Parameter list
description : string
}
type T = {
name : TypeName
variants : List<Variant>
description : string
}
module Record =
type T = {
name : TypeName
description : string
fields : List<Parameter>
}
type CompoundType =
| RecordType of Record.T
| EnumType of Enum.T
// existing type
type executionState = {
... // existing fields
userTypes = Map<UserTypeName, CompoundType>
builtinTypes = Map<StdlibTypeName, CompoundType>
packageTypes = Map<PackageTypeName, CompoundType>
}
// existing type
type DType =
... // existing variants
| CompoundType of CompoundType
// existing type
type Dval =
... // existing variants
| DRecord of { typeName: typeName; fields : (string * Dval) list}
| DEnum of { typeName: typeName; enumName of string; args of Dval list }
v2 Standard library
let optionType : CompoundType =
EnumType {
name = StdlibTypeName { module_ = "Result", typeName = "Result", version = 0 }
variants =
}
v2 Editor changes
Type aliases
Description
Dark v1 Problems
Title
Problem:
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Traits
Traits are one way to provide generics or ad-hoc polymorphism.
Dark v1 Problems
Many of the things that relied on "magic" in v1 could be solved with Traits. Thoughts:
- Trait for how to pretty-print for users
- Trait for hooking a value into a visualization system in the editor
- Trait for the SQL query compiler?
- Trait for addition, subtraction, etc
- maybe there's a set of known binops and they have traits defined for each of them
- fromJSON, toJSON
- Should implementations be implicitly derived, or explicitly derived and editable?
Open questions:
- support we have a type A, and users are using type A. Can we add trait B to type A? Probably not, that would change its behaviour. So we'd have to make type A1, with that trait.
- This could cause type explosion, so we'll need to automatically generate ways to convert types to/from different versions that are structurally the same
v2 Spec
v2 Language definition
v2 Standard library
v2 Editor changes
Modules and Namespacing
Modules and namespaces are used to separate functions and types so that they can have the same names without treading on each other.
Dark v1 Problems
Package manager function names are ugly
Problem:
Solution: TODO
Status: Design needed
Built-in types have no module
Problem: Ok, Error, Just and Nothing are not in any namespace
Solution: Ok should be
Status: Design needed
Built-in types have no module
Problem: Ok, Error, Just and Nothing are not in any namespace
Solution:
Status: Spec'ed or not spec'ed
v2 Spec
v2 Language definition
type FQFnName =
| Stdlib { module = string, name = string, version = int }
| PackageManager
{ owner = UserID,
package = string,
module = string,
name = string,
version = int
}
v2 Standard library
v2 Editor changes
JSON handling
Language versioning
Dark needs to be able to support evolution of the language. We intend to have different versions of the language, removing old language features and adding better ones.
At the same time, we have a goal that customers experience no downtime. We also don't want language versions to become a burden either to users or to us.
Evolving within a single language version
As we control the language implementation, and all running instances of it, we can make changes to the language if we can make them fully compatible (or one deemed so close to fully compatible that no-one will be bothered by it). The F# rewrite is one example of this, and we made a number of different changes to Dark in this version which were compatible:
- added a real type system
- this was compatible as the type system was barely used
- switch to bigint
- since we didn't actually know what the overflow behaviour was, this was deemed safe
- changed
FnCalltoApply, technically making functions first-class (rather than just passing around lambdas)
Some other changes we should be able to do:
- Remove
nulland change all instances toNothing- Definitely some open questions on this
- Change variable, function and DB definitions to use an ID instead of looking it up by name
- Add Worker global vars like we have DB global vars
- Move OK/Nothing/Error/Just into types
- Move uuid, date and httpresponse into types
To keep this safe, we need a definition of what is a "safe" change. For example, we currently believe that changing error messages should be allowed to be a "Safe" change. To allow this, we need to inform users what behaviour we believe is changeable without notice, and to discourage the use of that behaviour.
Support for multiple language versions
Sometimes there's a change which can't be done fully-compatibly. In order to support this, we want to make multiple versions of the language. This means, that we'll always need an implementation of the following for all language versions:
- RuntimeTypes
- ProgramTypes
- toEnduser serialization function
- toPrettyMachineReadable serialization function
- toRoundtrippable serialization function
- toQueryable serialization function
- a way to indicate which language version some data is serialized with
- a conversion function to/from the
n-1language version - a conversion function to/from the
n + 1language version
Versioning code
User code needs to be versioned. Users will need to version functions, handlers and types. Each one can be versioned individually.
Dark stdlib functions are typed by the some version. If we add a new v7 of the language, what should happen to a stdlib function (call this myFunc_v2) that returns v6. Options:
- add
myFunc_v3which returns v7 - change
myFunc_v2so that it returns a v7 value - we could also change it where appropriate and version it where appropriate
Interactions between language versions
Suppose we have a handler with v6 code, and it calls a function with v7 code. What should happen? Obviously, the v6 arguments should be converted to v7, the code should be run, and the v7 return value should be converted to v6.
This should work for any simple cases of calling code. Handlers calling functions, functions calling functions, handlers/functions emitting to other workers.
What about if we're trying to store a v7 value in a DB with type v6? We would convert the value to v6 and then store it.
Transitioning between language versions
Handlers should always aim to be on the latest version, as should functions.
But what about types and DBs? Should they even have language versions? What benefit would that bring? For storing a value in a DB, rows already have a Dark type field. That could represent the language version and we tell us which serializer to use. Then the retrieved value would be of a particular version and can be converted appropriately.
Types don't have any code associated with them to be versioned (though if they did, presumably we could version those functions). So it's not really clear why we'd have language versions for types, and what that would mean. So we can ignore this for now.
Migrating code automatically for users
Flags?
Dark should have a single version number, even if for example there is no difference between types in v2 and v3.
Editor
Help understanding
Dark v1 problems
Users often have problems understanding what they're seeing, for a number of reasons:
- they are learning the language for the first time, and are unfamiliar with the constructs, frameworks, types, functions, etc
- the editor prints things in an ambiguous way
Solution
We already partially solve this with traces, where we show actual values. However, we can show more information to help:
- show the type in the live value display
- show
(i)info icon on framework elements, types. This will show a doc for this, perhaps with a link to more information - an "AST view" where you can see the AST of this code, and when you mouse over particular code you see the AST you're selecting
Error messages
Dark v1 problems
- Error messages don't have stacktraces (we lose context)
- Error messages are shown as a red bar, rather than appearing where the error occurs
- Errors are not tracked, and devs are not alerted to the presence of errors (eg like in Rollbar, bugsnag, etc)
Fluid editor
Dark v1 problems
Different editing schemes
Problem: Dark has two different ways of editing text. The "blankOr" method where something is blank or has a value, and the fluid method of editing code. The fact that there are two is confusing, as they have different interaction models (they also intersect badly).
Solution: The Fluid method is far superior, so make it so we can edit databases, handlers, functions, using Fluid editing
- note that some places have the ability to do cool shit now (eg, dragging function parameters to a different order); we should super-impose nice editing tooling like this on fluid tokens
Unclear how to change text
Problem: while it's relatively nice to create text, changing existing code is a bit of an ordeal.
Solution: We need to identify a (large) list of specific areas where changing code is annoying, and find ways to make them nice, whether using refactoring tools, overlays, keyboard shortcuts, copy/paste, or just typing
List of known problems:
- TODO
Text Wrapping
Problem: We wrap text in a number of places (strings at 40 characters), function calls at 120 characters. We need to wrap more things.
Solution: Write down how wrapping should work for various constructs.
Precedence
Problem: It's difficult for users to set (or to see) the precedence of code in Dark. For example: i % 15 == 0 , if typed out left-to-right in the way you'd expect, is actually i % (15 == 0).
**Solution (seeing precedence): **the code is actually in the repo for displaying parens around expressions when they need them. It just needs:
- to be enabled
- to be trimmed so that we only show them at useful times (eg
1 + 1doesn't need it, buti % 15 == 0does)
The major issue that made this challenging is that when you add an expression which needs parens, it adds a parenthesis behind you, which moves your cursor. When we had a caret which uses an integer offset as position, this would keep it in the same place and that would be really annoying. We switched to AstRefs instead (the caret is now determined relative to a particular AST element), but we probably still have some bugs that will come from this.
**Solution (automatically setting precedence): **when typing infix, there is a known set of precedence rules that humans expect (most languages define them in the parser). As a result, we should use them to automatically set precedence as users type.
**Solution (allowing users change precedence): **once you've got a particular precedence, how do you change it? We don't allow you to type parens randomly, or to delete them. Instead, we should add refactoring commands to shift what's covered in the parens. Paredit (one of the inspirations for Dark's editor) does this really well.
Undo is slow
Problem: when undoing something in Dark, it can take a long time and you can't see that.
Solution: make it faster. Dark opcodes are often huge and pulling them all from the DB, then writing them back, does indeed take time.
- We can shrink the opcodes significantly (most opcode in the DB are SetHandlers, which contain the entire handler. Switching to much smaller opcodes such as
SetExprandInsertIntoStringAtwould result in much much smaller ops. - We can also send fewer opcodes when a user is typing (eg a long string) by debouncing.
- We can cache previous states in the client or server
- We can make the opcodes so that we can go both ways
Solution: make it clear that something is happening. There should be an indicator to let you know that Dark is actually undoing your code for you.
Undo is broken for function/DB renames
Problem: if you rename a function, it will rename all users of that function. If you then undo a handler with a use in it, it will go back to the old name (which breaks it). If you undo a function name change, none of the uses are updated.
Solution: we could store the TLIDs of functions being called and the DBs being referenced, instead of their names. Then renames wouldn't be needed, and wouldn't be part of the undo stack
Permissions model
Dark should support fine-grained permissioning
Dark v1 Problems
Only owners exist
Problem: Users who are added to orgs become owners
Solution: Allow different permissions, and create common roles to reflect them
Status: Design needed
Public canvases are not yet supported
Problem: We'd like users to show off their canvases (and may even make this the default)
Solution: We need enough permissions that this is safe to do
- Should be able to disable traces on a canvas
- Secrets should actually be secret
- We need a subset of traces that provide value,
Status: Spec needed
v2 Spec
Trace design:
- By default, traces are private, even on public canvases (can be made public, opt-in)
- A subset of traces are shown to users
- just the fact that they exist
- when traces have users, show something else, like flags of the country the IP address is from
- Default values are generated for each type to help who are contributing
Collaboration
Dark v1 problems
Users can't see what changes were made, when, or by who?
Problem: when you go to look at some code, sometimes it looks wrong? Which idiot made that change (and was it, in fact, me)? Lacking the ability to see changes
Solution: store the user and the timestamp on ops
TODO: notifications for changes. Look at what notion/slack does, work in github too.
Ops
- undo
- operational transforms / collaboration
- edits are too big
- reduce size
- debounce
Refactoring commands
- Editing commands should be part of the main autocomplete, not special
- should be able to add them to packages
- Should support being able to set keyboard shortcuts for refactoring commands
What commands should be available?
- move to next/prev spot in list (eg in tuple, list, record, match, pipe)
- insert all fields of this record
Feature flags
Global feature flags
Open questions
- how can we flag the input/output type of a handler
Canvas / code organization
Dark v1 problems
Code layout
The layout of code in Dark v1 is ugly and unloved. It was a compromise to get it shipped, but not what's actually needed.
The vision for how we display code in the editor is called the "Architectural View". It's intended as a better way to view your components of your infrastructure than files and folders. Instead, you view your infrastructure according to its structure - that is, the same way you would see it if a senior engineer was drawing your infrastructure on the whiteboard.
An example:
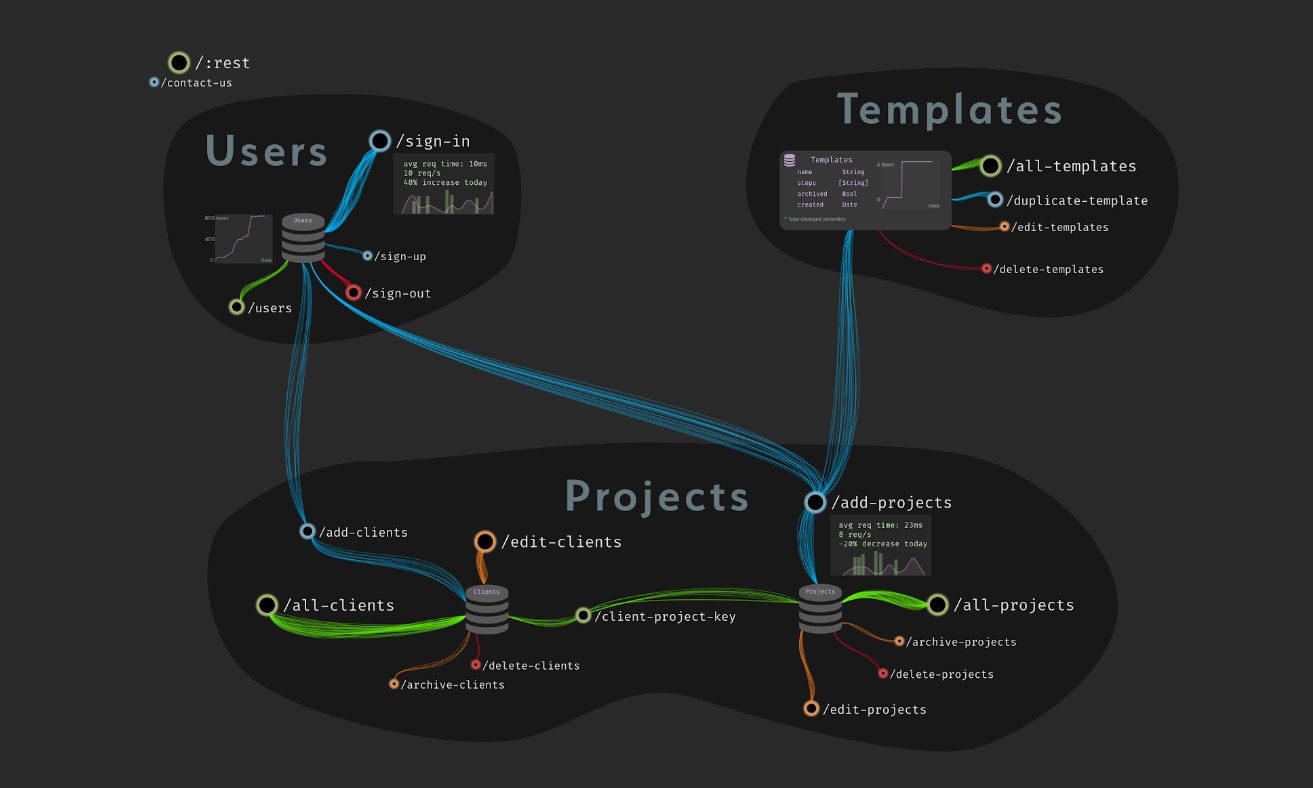
This is a simple app that probably does something like project tracking, and it has 3 services: users, templates, and projects. Each of the HTTP routes is clustered around the database that they affect. Some of the DBs and routes have stats showing. The lines between the different routes represent traffic.
Problems
- dark code is currently in "boxes" that users drag around
- some users drag them to high precision and it bothers them if they're not lined up. Of course, they grow when you add code!
- users can't see multiple functions at the same time
- we currently load the entire canvas at once, which can sometimes be too big
- no way to group things
- Users have many canvases. The intent was for users to have a single canvas with everything in it.
- Need a way to display modules that's separate from how we display "structural" components
Solutions:
- implement the architectural view
- find a way to display modules of functions/types that's not the architectural view
- add grouping of canvas elements, reimplement multiple canvases as a single canvas with multiple groups.
Profiler
In Dark v1:
- it's hard to know how long things take
- it's hard to know when things are slow
- it's very hard to know why
Accounts
Dark supports both users and organizations, in a similar way that GitHub does
Dark v1 Problems
Only Dark employees can create organizations
Problem: There is no UI for organizations
Solution: Add UI, using a Dark canvas
Status: Spec'ed or not spec'ed
Users and orgs are the same thing
Problem: It seems that it's wise to separate user and orgs somehow. We should do that.
Solutions:
- figure out best practices
- should not be possible to login as an org (we've been implementing this by having the username be a dark email and the password be invalid)
- keep orgs and
Status: Need to investigate best practices and make a design
Can't rename username or orgs
Problem: We would like to rename usernames or orgs. The main issue is that the builtwithdark urls would change
Solution:
- stop using user.builtwithdark.com and create a new URL per canvas (or possibly multiple per canvas) using darklang.io
- then allow users to change their username, validating the same rules as otherwise exists
Status: Need to spec darklang.io naming, and forwarding and deprecation policy for builtwithdark.com
No trademark/usage policy for username
Problem: Companies get into trouble when they make changes to usernames. Users are very protective of their identities so we should establish rules and norms early
Solution:
- investigate best practices
- Some obvious rules
- Users can't sell usernames (any financial transaction would result in the domain being taken)
- No squatting
- Allow company to re-allocate usernames in event of abuse, significant confusion, or squatting, dead accounts
Status: TODO
Framework
Error Tracking
Developers need to feel safe that Dark works. Right now, it is impossible (or at least extremely challenging) to know if your users are having issues, if all webhooks are being accepted, etc. Requests may hit Dark but hit an error of many kinds, and that error will create a trace that is hard to find.
Categories of error:
- runtime errors
- coding error:
- an incomplete value appears
- unexpected function error
- a DError (Dark built-in error)
- unhandled exception
- DErrorRail - an error path reaches the user with Error/Nothing
- an expected unexpected value
- Non-200 results
- dev-defined assertion
- coding error:
- "compile time"
- unit tests not passing
- uses of deprecated functions
- other
- can users add bugs, TODOs, etc, in here.
- Can users add things in here dynamically?
Problem: developers should be able to discover the error
Solution: Error traces should be put in a dead-letter queue, which have urls
Solution: Developers should be notified about errors. One implementation is that there would be a default error handler for the whole canvas, which would email the developer for each error (potentially every nth error). As an extension, this handler could be customized (if there is an error in the customization, the default handler would run again).
Solution: the canvas should have a list of TODO items, which should include errors in the error tracker
Problem: developers should be able to solve the error
Solution: When an error is found, the notification should link to the trace. The trace should be replayable (either fully or partially) using existing trace features, which would allow the developer to ensure the intended action still happens for their user. The dev should then able to to resolve it.
Solution: If there are a lot of errors, the user should be able to handle them all. For example, all of them could be pushed into a standard queue to be processed. If this is done, a button to run just one queue entry would be extremely valuable.
HTTP handlers
Problem
Dark v1 had an implicit HTTP framework that was limited, opaque, and inflexible.
Problems with the Dark v1
- Users could not change how we processed a HTTP request
- other encodings aren't supported and can't be added
- you can't upload video or other "bytes" and things that aren't strings
- Headers in HTTP should be allowed to be specified twice
- No input validation for any fields
- you can validate manually which is really annoying
- a JSON field is not type checked and could be any type
- empty request body (with just incompletes) was impossible to use
- magic sending did not match the magic receiving
- No way to specify a 404 or a 500 handler
- No way to match arbitrary HTTP methods
- Can't have a HEAD handler (the framework converts the request to a GET)
- Should the standard 404 have a content-type header
- if you return a string, it shouldn't have quotes, right? I mean it already is ct: text/plain
- locking
Solution 1: middleware
We want to support the creation of middleware stacks, collections of functions which transform HTTP requests and responses in a common way. These would allow:
- users to customize how input to HTTP handlers is created
- separate handling for authenticated and unauthenticated routes
- gradually adding support for partially implemented features (for example, v1 Dark can read latin1 and utf8, but not other encodings)
- potentially graphql support could be a different middleware
Middleware stacks are pretty common in other languages, Python (WSGI) and Clojure (Ring) being the two I'm most familiar with.
A middleware stack is simply a function wrapping another function.
If we have a function handle(req : Request) -> Response, then a middleware handler is a functionmiddleware(innerFn : Request -> Response) -> (Request -> Response) (that is, it takes as an argument a function and returns a function, and both the parameter and returned functions take a request and return a result).
What's in the Dark v1 "middleware"?
- The Dark middleware is complicated and works poorly.
Responses
- Anytime we infer a content-type, the content type is
text/plain; charset=utf-8unless the value is an Object or List, in which case it isapplication/json; charset=utf-8 - If the response is a HttpResponse value, then we infer a content-type if none exists, then convert it to json or plain text using built-in functions
- If the response in a HttpRedirect response, the value is ignored.
- If the response is on the ErrorRail, a response of 404 is returned (**Note: **even if the ErrorRail is an Error)
- If the response is a DError, a 500 is returned with an error message.
- If the response is none of these, then we convert it to JSON and infer the header, using a code of 200. Note: this often gives a JSON string response with a text/plain header. this is unexpected and bad, and also the most common outcode. Instead it should content-negotiate
- Cors headers are then added, based on the CORS settings in the canvas
- The value is then converted to Bytes, and returned to the caller
- At no point does Dark do any content-negotiation
Requests
- parsing path segments and inserting into the symtable
- returning 418 for text/ping
- creating a request object with formBody, jsonBody, cookies, url, body
- automatically respond to HEAD for GET requests. Currently HEAD handlers can be created but will not be hit
- automatically handling OPTIONS/CORS
- using the dark favicon if none is provided
- returning a blank sitemap or favicon
- converting response to JSON string
- converting response to other type?
Desired changes in Dark v2 http middleware:
- no special response for text/ping content types
- all headers should be lowercase in requests
- remove the x-forwarded-for, x-real-ip, x-forwarded-proto and x-forwarded headers
- set the URL correctly
- add an IP address to the uri object
- set the server to darklang
- improve the cors middleware to make it seemless and safe
- Add a type to allow users to specify their cors domain/null, etc
- by default, return localhost:ANYTHING if that's provided
- use good default headers
- remove the Connection header
- support multipart form data
- requests should support plain text
- request bodies in GET should be allowed
- accept-encoding should be responded too automatically
How would users create, edit, and delete a middleware?
- middleware is just a function with a specific type signature
- each step in the middleware would have to type check with the previous middleware
- final middleware shows the type of request
Where would users specify a middleware for their handler?
- the editor would allow the choice. HTTP uses the default stack (defined at handler creation time), and you can change the middleware stack directly, including changing to use the "feature flag middleware" stack
How would users change the middleware of some handler or set of handlers (eg feature flags)?
- a feature flag middleware which chooses which of the two middleware stacks to process
Implementation
Middlewares
Middlewares are typed functions that contribute a small, composable part of decoding a web request for the handler to use. Middlewares receive a request, and then based on the request, may choose to call the next middleware or simply return a response instead. As such, middlewares receive as parameters both the request so far, as well as the next middleware to call. They are responsible for calling the next middleware, possibly changing the request first and possible altering the response as well. This leads to middlewares having the following shape:
let myMiddleware (arg : myMiddlewareArgType) next =
fun (req : 'req) ->
let doSomethingToRequest req = { req with someExtraField = someFunction req }
let doSomethingToResponse res = { res with someExtraField = someFunction res }
let shortCircuitResponse = { status = 404, body = "", headers = [] }
if someCondition req
then shortCircuitResponse
else req
|> doSomethingToRequest
|> nextMiddleware
|> doSomethingToResponse
A middleware returns a function which takes a request. A middleware takes whatever arguments it needs, as well as the next middleware to call. As such, a middleware stack looks like this:
let middleware =
(\ctx -> handler ctx) // shown like this for clarity
|> addQueryParams url
|> addHeaders headers
|> readVarsFromURL
|> addJsonBody headers body
|> addFormBody headers body
|> addCookies headers
|> processErrorRail
|> optionsHanderMiddleware
|> headHandlerMiddleware
|> textPingMiddleware
|> sitemapFaviconMiddleware middleware emptyRequest
Each middleware wraps the previous one, so the outermost middleware is last, and the handler comes first.
EmptyRequest is an empty record, and each middleware adds fields to it until the request has the shape required by the handler. It then returns a response, which can also have fields added to it by middleware wishing to send those fields to other middlewares.
As such, the types of the entire middleware have to add up to the type of the handler.
Editor integration
How do we write out HTTP handlers in fluid, taking into account middleware?
// idea: type http::GET, and it fills out the parameters path and response
http::GET
path : ___
response : ___
___
// then we fill in the values and we get
http::GET
path : /hello/:name/:age
name : String
age : String
response :
// these are defined by middleware such as:
fn get_body(raw_req :: HTTP::Request, user_obj,
Problem: we don't have anyway to dynamically create data in a type sensitive way. I want the handler to say "there is this value _body_ that you now have available", how can I do that?
- Can the user_obj just be untyped and everything writes to it and we know it's type because the type checker figures it out?
- add fields like in elm, start with an empty record and add fields to it. Type checks the whole way down
GraphQL
Dark v1 problems
No GraphQL
Problem: GraphQL is one of the most asked-for additions to Dark. It's also a massively growing area, that promises to reduce accidental complexity compared to REST/JSON APIs. Dark has no GraphQL ability, though users have built GraphQL APIs on Dark.
Solution: Design an easy way to create GraphQL APIs for types and DBs. (As a non-expert, I hope this is a place the community will make suggestions).
Datastores
Do we need DB::query, or can we pre-process the actual implementations (is there a trait to type check it, the query returns a lazy value that gets built up?) how does that work?
DB schema
Migrations
Workers
Dark v1 problems
- Queues should be processed with QoS. If someone puts 100k items in the queue, the user with just 1 should still go immediately.
- V1 doesn't have the ability to fanout, or do any patterns except emit
- We dont have a good understanding of the currently implemented retry logic, or what the retry logic should be
- users dont have a good way to get warnings if their queues are failing
- maybe add a dead-letter queue
- no way to introspect queues using code, barely any way to introspect them without code
- sometimes queues take too long or fail, and items build up. should they be rerun? Should there be an expiry time?
- Queues don't autoscale
- perhaps we shouldn't be using built-in queues and should istead of cloud-y queues
Cron / scheduled jobs
Why do people need every 1m calls to the queue?
- users often ask to be able to run an event at a particular time
- the implementation of our queues would actually allow this quite nicely
Traces / analysis / tests
- Dark feels unsafe to users
- size of traces is out of control
- when moving around the editor, we don't stay in the same trace
- nothing works if you don't have traces
Storage of traces
Problem: the storage of traces is poor. Each trace is currently stored and then GCed - the performance of the GC is poor, despite multiple incremental fixes, and causes operational issues.
Solution: The trace feature should be redesigned with performance taken into account. The access patterns are:
- traces are created on each request. They are created in several parts and written to the DB each time. The inputs are written on input (they are stored with the path, module, and modifier instead of a tlid, to allow searching for 404s. It also means that 404s are created dynamically. The intent was for 404s to be automatically repopulated when changing the name of a canvas: this feature is alsp confusing to users)
- traces are updated via:
So
- store 404s separately
- new handler and function executions get new traces
- store trace data in S3/Cloud Storage
- add rate limiting so we only store a subset of traces (make configurable)
Traces don't work well in functions
Problem: when you create code in a function for the first time, the function does not have a trace, and the arguments are Incomplete. This means everything is red and when you try to call functions, nothing works.
Why? The system is built around trace-driven development, but if you don't have a trace, nothing works.
Solution: Add a warning that you're using the default trace and it doesn't have values for the arguments. Fade the Play button and show a warning about this. Or at least give an error when you try to run something with an incomplete in it.
Solution: Perhaps default traces should use default values for known types. However, that will result in real values being put in the DB, which the user will then have to dig out.
Solution: perhaps a dry-run of some sort might be an idea in this situation?
Domain registration
Static assets
Infrastructure
The infrastructure needs to be async
Program storage
- when loading a handler, we also load every function, etc, not just the necessary ones. We should store the dependencies with the code (this could be done in the client)
Libraries
Package manager
Most of the libraries in Dark, especially for access to 3rd party services (Twitter, Stripe, etc), will be provided by users in the package manager.
Packages will have a naming scheme similar to github (username/package, eg "darklang/tablecloth") and a module and versioning system like Dark's current stdlib (module::function_version, eg "String::trim_v1").
Dark v1 problems
- In Dark, packages do not have versions, their contents do. Individual functions, types, etc, are versioned, and once added to a package are never removed. Instead, they can be deprecated by future functions.
- TODO: how do we slow roll out new versions if we're not sure they're ready?
- TODO: do we address functions by hash/ID, or by name?
- What is the mechanism to upload functions?
- What about dependencies?
- TODO: nested modules
- How do traces work? we want traces to be available to users of functions, and we want to allow users to be able to submit traces to package managers (probably with info redacted)
Other
In all languages, there is a question of allowing the user to add functions to libraries they don't control. Given a function module.x, they want to add module.x1 which is sort of different, without having to write MyModule.x1 instead. JS and Ruby use monkey patching, in C++ and F# you can open the module and add to it. In Java you use inheritance, sorta.
In Dark, you add a function which is in a different namespace, but the editor makes it feel like you didn't. So if you've added mymodule/stdlib/String::trimDifferent, the editor will show you String::trimDifferent instead. Unless there is another String::trimDifferent in scope, in which case it will disambiguate.
Definition of a package, v2
A dark toplevel is a namespace, defined as <owner>/<package>/<module>::<item>_<version>. The owner is the user or organization who owns it, similar to github. similar to github. Within this namespace,
Security
- dont allow access to global variables (DBs)
- only allow httpclient calls to know domains
- packages must typecheck
Standard packages
The dark standard library is within dark/stdlib.
TODO
HTTPClient calls
TODO: JSON deserialization
Style guide
- If converting between less-specific and more-specific types, put the conversion functions in the more specific type
- eg
UUID::parse (String) -> UUID - eg
String::toInt (String -> Int)
- eg
Dark v1 stdlib
Dark v1 stdlib
!=(Any a, Any b) -> Bool
%(Int a, Int b) -> Int
&&(Bool a, Bool b) -> Bool
*(Int a, Int b) -> Int
+(Int a, Int b) -> Int
++(Str s1, Str s2) -> Str
-(Int a, Int b) -> Int
/(Float a, Float b) -> Float
<(Int a, Int b) -> Bool
<=(Int a, Int b) -> Bool
==(Any a, Any b) -> Bool
>(Int a, Int b) -> Bool
>=(Int a, Int b) -> Bool
^(Int base, Int exponent) -> Int
||(Bool a, Bool b) -> Bool
emit_v1(Any event, Str Name) -> Any
equals(Any a, Any b) -> Bool
notEquals(Any a, Any b) -> Bool
toString(Any v) -> Str
AWS::urlencode(Str str) -> Str
Bool::and(Bool a, Bool b) -> Bool
Bool::isNull(Any check) -> Bool
Bool::not(Bool b) -> Bool
Bool::or(Bool a, Bool b) -> Bool
Bool::xor(Bool a, Bool b) -> Bool
Bytes::base64Encode(Bytes bytes) -> Str
Bytes::hexEncode(Bytes bytes) -> Str
Bytes::length(Bytes bytes) -> Int
Crypto::md5(Bytes data) -> Bytes
Crypto::sha1hmac(Bytes key, Bytes data) -> Bytes
Crypto::sha256(Bytes data) -> Bytes
Crypto::sha256hmac(Bytes key, Bytes data) -> Bytes
Crypto::sha384(Bytes data) -> Bytes
DB::count(Datastore table) -> Int
DB::deleteAll_v1(Datastore table) -> Nothing
DB::delete_v1(Str key, Datastore table) -> Nothing
DB::generateKey() -> Str
DB::getAllWithKeys_v2(Datastore table) -> Dict
DB::getAll_v3(Datastore table) -> List
DB::getExisting(List keys, Datastore table) -> List
DB::getManyWithKeys_v1(List keys, Datastore table) -> Dict
DB::getMany_v3(List keys, Datastore table) -> Option
DB::get_v2(Str key, Datastore table) -> Option
DB::keys_v1(Datastore table) -> List
DB::queryCount(Datastore table, Block filter) -> Int
DB::queryExactFields(Dict spec, Datastore table) -> List
DB::queryExactFieldsWithKey(Dict spec, Datastore table) -> Dict
DB::queryOneWithExactFields(Dict spec, Datastore table) -> Option
DB::queryOneWithExactFieldsWithKey(Dict spec, Datastore table) -> Option
DB::queryOneWithKey_v3(Datastore table, Block filter) -> Option
DB::queryOne_v4(Datastore table, Block filter) -> Option
DB::queryWithKey_v3(Datastore table, Block filter) -> Dict
DB::query_v4(Datastore table, Block filter) -> List
DB::schemaFields_v1(Datastore table) -> List
DB::schema_v1(Datastore table) -> Dict
DB::set_v1(Dict val, Str key, Datastore table) -> Dict
Date::<(Date d1, Date d2) -> Bool
Date::<=(Date d1, Date d2) -> Bool
Date::>(Date d1, Date d2) -> Bool
Date::>=(Date d1, Date d2) -> Bool
Date::add(Date d, Int seconds) -> Date
Date::atStartOfDay(Date date) -> Date
Date::day(Date date) -> Int
Date::fromSeconds(Int seconds) -> Date
Date::greaterThan(Date d1, Date d2) -> Bool
Date::greaterThanOrEqualTo(Date d1, Date d2) -> Bool
Date::hour_v1(Date date) -> Int
Date::lessThan(Date d1, Date d2) -> Bool
Date::lessThanOrEqualTo(Date d1, Date d2) -> Bool
Date::minute(Date date) -> Int
Date::month(Date date) -> Int
Date::now() -> Date
Date::parse_v2(Str s) -> Result
Date::second(Date date) -> Int
Date::subtract(Date d, Int seconds) -> Date
Date::toSeconds(Date date) -> Int
Date::toString(Date date) -> Str
Date::toStringISO8601BasicDate(Date date) -> Str
Date::toStringISO8601BasicDateTime(Date date) -> Str
Date::today() -> Date
Date::weekday(Date date) -> Int
Date::year(Date date) -> Int
Dict::empty() -> Dict
Dict::filterMap(Dict dict, Block f) -> Dict
Dict::filter_v1(Dict dict, Block f) -> Dict
Dict::fromList(List entries) -> Option
Dict::fromListOverwritingDuplicates(List entries) -> Dict
Dict::get_v2(Dict dict, Str key) -> Option
Dict::isEmpty(Dict dict) -> Bool
Dict::keys(Dict dict) -> List
Dict::map(Dict dict, Block f) -> Dict
Dict::member(Dict dict, Str key) -> Bool
Dict::merge(Dict left, Dict right) -> Dict
Dict::remove(Dict dict, Str key) -> Dict
Dict::set(Dict dict, Str key, Any val) -> Dict
Dict::singleton(Str key, Any value) -> Dict
Dict::size(Dict dict) -> Int
Dict::toJSON(Dict dict) -> Str
Dict::toList(Dict dict) -> List
Dict::values(Dict dict) -> List
Float::absoluteValue(Float a) -> Float
Float::add(Float a, Float b) -> Float
Float::ceiling(Float a) -> Int
Float::clamp(Float value, Float limitA, Float limitB) -> Float
Float::divide(Float a, Float b) -> Float
Float::floor(Float a) -> Int
Float::greaterThan(Float a, Float b) -> Bool
Float::greaterThanOrEqualTo(Float a, Float b) -> Bool
Float::lessThan(Float a, Float b) -> Bool
Float::lessThanOrEqualTo(Float a, Float b) -> Bool
Float::max(Float a, Float b) -> Float
Float::min(Float a, Float b) -> Float
Float::multiply(Float a, Float b) -> Float
Float::negate(Float a) -> Float
Float::power(Float base, Float exponent) -> Float
Float::round(Float a) -> Int
Float::roundDown(Float a) -> Int
Float::roundTowardsZero(Float a) -> Int
Float::roundUp(Float a) -> Int
Float::sqrt(Float a) -> Float
Float::subtract(Float a, Float b) -> Float
Float::sum(List a) -> Float
Float::truncate(Float a) -> Int
Http::badRequest(Str error) -> Response
Http::forbidden() -> Response
Http::notFound() -> Response
Http::redirectTo(Str url) -> Response
Http::response(Any response, Int code) -> Response
Http::responseWithHeaders(Any response, Dict headers, Int code) -> Response
Http::responseWithHtml(Any response, Int code) -> Response
Http::responseWithJson(Any response, Int code) -> Response
Http::responseWithText(Any response, Int code) -> Response
Http::setCookie_v2(Str name, Str value, Dict params) -> Dict
Http::success(Any response) -> Response
Http::unauthorized() -> Response
HttpClient::basicAuth_v1(Str username, Str password) -> Dict
HttpClient::bearerToken_v1(Str token) -> Dict
HttpClient::delete_v5(Str uri, Dict query, Dict headers) -> Result
HttpClient::formContentType() -> Dict
HttpClient::get_v5(Str uri, Dict query, Dict headers) -> Result
HttpClient::head_v5(Str uri, Dict query, Dict headers) -> Result
HttpClient::htmlContentType() -> Dict
HttpClient::jsonContentType() -> Dict
HttpClient::options_v5(Str uri, Dict query, Dict headers) -> Result
HttpClient::patch_v5(Str uri, Any body, Dict query, Dict headers) -> Result
HttpClient::plainTextContentType() -> Dict
HttpClient::post_v5(Str uri, Any body, Dict query, Dict headers) -> Result
HttpClient::put_v5(Str uri, Any body, Dict query, Dict headers) -> Result
Int::absoluteValue(Int a) -> Int
Int::add(Int a, Int b) -> Int
Int::clamp(Int value, Int limitA, Int limitB) -> Int
Int::divide(Int a, Int b) -> Int
Int::greaterThan(Int a, Int b) -> Bool
Int::greaterThanOrEqualTo(Int a, Int b) -> Bool
Int::lessThan(Int a, Int b) -> Bool
Int::lessThanOrEqualTo(Int a, Int b) -> Bool
Int::max(Int a, Int b) -> Int
Int::min(Int a, Int b) -> Int
Int::mod(Int a, Int b) -> Int
Int::multiply(Int a, Int b) -> Int
Int::negate(Int a) -> Int
Int::power(Int base, Int exponent) -> Int
Int::random_v1(Int start, Int end) -> Int
Int::remainder(Int value, Int divisor) -> Result
Int::sqrt(Int a) -> Float
Int::subtract(Int a, Int b) -> Int
Int::sum(List a) -> Int
Int::toFloat(Int a) -> Float
JSON::parse_v1(Str json) -> Result
JWT::signAndEncodeWithHeaders_v1(Str pemPrivKey, Dict headers, Any payload) -> Result
JWT::signAndEncode_v1(Str pemPrivKey, Any payload) -> Result
JWT::verifyAndExtract_v1(Str pemPubKey, Str token) -> Result
List::append(List as, List bs) -> List
List::drop(List list, Int count) -> List
List::dropWhile(List list, Block f) -> List
List::empty() -> List
List::filterMap(List list, Block f) -> List
List::filter_v2(List list, Block f) -> List
List::findFirst_v2(List list, Block f) -> Option
List::flatten(List list) -> List
List::fold(List list, Any init, Block f) -> Any
List::getAt_v1(List list, Int index) -> Option
List::head_v2(List list) -> Option
List::indexedMap(List list, Block f) -> List
List::interleave(List as, List bs) -> List
List::interpose(List list, Any sep) -> List
List::isEmpty(List list) -> Bool
List::last_v2(List list) -> Option
List::length(List list) -> Int
List::map(List list, Block f) -> List
List::map2(List as, List bs, Block f) -> Option
List::map2shortest(List as, List bs, Block f) -> List
List::member(List list, Any val) -> Bool
List::push(List list, Any val) -> List
List::pushBack(List list, Any val) -> List
List::randomElement(List list) -> Option
List::range(Int lowest, Int highest) -> List
List::repeat(Int times, Any val) -> List
List::reverse(List list) -> List
List::singleton(Any val) -> List
List::sort(List list) -> List
List::sortBy(List list, Block f) -> List
List::sortByComparator(List list, Block f) -> Result
List::tail(List list) -> Option
List::take(List list, Int count) -> List
List::takeWhile(List list, Block f) -> List
List::uniqueBy(List list, Block f) -> List
List::unzip(List pairs) -> List
List::zip(List as, List bs) -> Option
List::zipShortest(List as, List bs) -> List
Math::acos(Float ratio) -> Option
Math::asin(Float ratio) -> Option
Math::atan(Float ratio) -> Float
Math::atan2(Float y, Float x) -> Float
Math::cos(Float angleInRadians) -> Float
Math::cosh(Float angleInRadians) -> Float
Math::degrees(Float angleInDegrees) -> Float
Math::pi() -> Float
Math::radians(Float angleInRadians) -> Float
Math::sin(Float angleInRadians) -> Float
Math::sinh(Float angleInRadians) -> Float
Math::tan(Float angleInRadians) -> Float
Math::tanh(Float angleInRadians) -> Float
Math::tau() -> Float
Math::turns(Float angleInTurns) -> Float
Option::andThen(Option option, Block f) -> Option
Option::map2(Option option1, Option option2, Block f) -> Option
Option::map_v1(Option option, Block f) -> Option
Option::withDefault(Option option, Any default) -> Any
Password::check(Password existingpwr, Str rawpw) -> Bool
Password::hash(Str pw) -> Password
Result::andThen_v1(Result result, Block f) -> Result
Result::fromOption_v1(Option option, Str error) -> Result
Result::map2(Result result1, Result result2, Block f) -> Result
Result::mapError_v1(Result result, Block f) -> Result
Result::map_v1(Result result, Block f) -> Result
Result::toOption_v1(Result result) -> Option
Result::withDefault(Result result, Any default) -> Any
StaticAssets::baseUrlFor(Str deploy_hash) -> Str
StaticAssets::baseUrlForLatest() -> Str
StaticAssets::fetchBytes(Str deploy_hash, Str file) -> Result
StaticAssets::fetchLatestBytes(Str file) -> Result
StaticAssets::fetchLatest_v1(Str file) -> Result
StaticAssets::fetch_v1(Str deploy_hash, Str file) -> Result
StaticAssets::serveLatest_v1(Str file) -> Result
StaticAssets::serve_v1(Str deploy_hash, Str file) -> Result
StaticAssets::urlFor(Str deploy_hash, Str file) -> Str
StaticAssets::urlForLatest(Str file) -> Str
String::append_v1(Str s1, Str s2) -> Str
String::base64Decode(Str s) -> Str
String::base64Encode(Str s) -> Str
String::contains(Str lookingIn, Str searchingFor) -> Bool
String::digest(Str s) -> Str
String::dropFirst(Str string, Int characterCount) -> Str
String::dropLast(Str string, Int characterCount) -> Str
String::endsWith(Str subject, Str suffix) -> Bool
String::first(Str string, Int characterCount) -> Str
String::foreach_v1(Str s, Block f) -> Str
String::fromChar_v1(Character c) -> Str
String::fromList_v1(List l) -> Str
String::htmlEscape(Str html) -> Str
String::isEmpty(Str s) -> Bool
String::join(List l, Str separator) -> Str
String::last(Str string, Int characterCount) -> Str
String::length_v1(Str s) -> Int
String::newline() -> Str
String::padEnd(Str string, Str padWith, Int goalLength) -> Str
String::padStart(Str string, Str padWith, Int goalLength) -> Str
String::prepend(Str s1, Str s2) -> Str
String::random_v2(Int length) -> Result
String::replaceAll(Str s, Str searchFor, Str replaceWith) -> Str
String::reverse(Str string) -> Str
String::slice(Str string, Int from, Int to) -> Str
String::slugify_v2(Str string) -> Str
String::split(Str s, Str separator) -> List
String::startsWith(Str subject, Str prefix) -> Bool
String::toBytes(Str str) -> Bytes
String::toFloat_v1(Str s) -> Result
String::toInt_v1(Str s) -> Result
String::toList_v1(Str s) -> List
String::toLowercase_v1(Str s) -> Str
String::toUUID_v1(Str uuid) -> Result
String::toUppercase_v1(Str s) -> Str
String::trim(Str str) -> Str
String::trimEnd(Str str) -> Str
String::trimStart(Str str) -> Str
Twilio::sendText_v1(Str accountSID, Str authToken, Str fromNumber, Str toNumber, Str body) -> Dict
Uuid::generate() -> UUID
X509::pemCertificatePublicKey(Str pemCert) -> Result
User module
One essential item in Dark is a User module. It should be trivial (take no more than 1 minute) to set up a user module. The user module should support:
- signing up, logging in and out
- password reset, including emailing
- password security - no visible passwords in a trace
- login with social accounts (where logins on multiple accounts can be combined)
- github, twitter, facebook and google, at least
- a primary key that is not an email address
- easy integration with React and Vue, as well as iOS and Android
- Easy-to-use, styleable, HTML pages
- Profile images (pre-populated from gravatar)
- Tight integration with traces - see a users' profile image on the trace
- Tight integration with feature flags - easily enable a flag for sets of users
- Cookies
- JWT
And it should aim to, in the future, support:
- Multi-factor auth
- allowing this be a login system for backends written in other systems
- adding other social accounts
- ability to see an audit log of a single user
- ability to automatically delete a single user's data for compliance reasons
- levels of authorization
TODO: